Prologue : Two facets of Customer management
Three choices : Spending to acquire new customers (7 X more expensive) or maintain the existing customers through focused customer value management (at X cost) or balance these 2 facets.

Business Intent : What do we want to know about our customers
Who are our customers and what can we do for them to keep them engaged
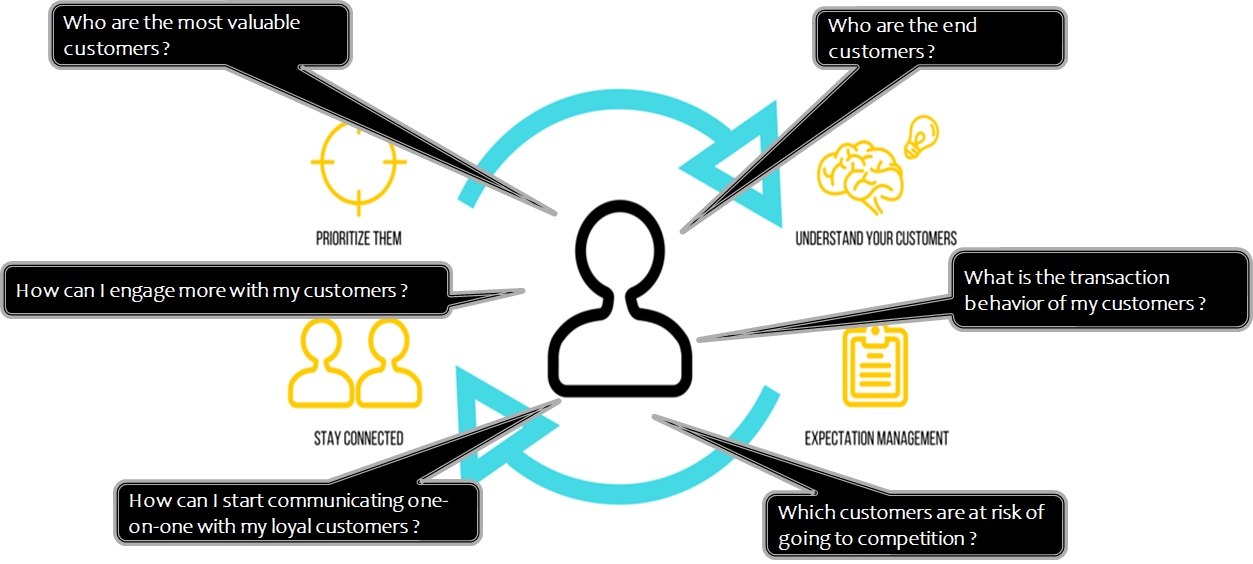
Basics of RFMC
The goal of RFMC Analysis is to segment customers based on transaction behavior. To do this, we need to understand the historical actions of individual customers for each RFMC factor. We then rank customers based on each individual RFMC factor, and finally pull all the factors together to create RFMC segments for targeted marketing.
Recency : How recently a customer transacted. (measure : time (day) since last activity)
Frequency: How many times a customer transacted. (measure : count of distinct transactions)
Monetary: Value (in money sense) of transaction. (measure : sum of transaction value)
Consistency: The regularity of transactions. (measure : distinct number of days (or weeks)
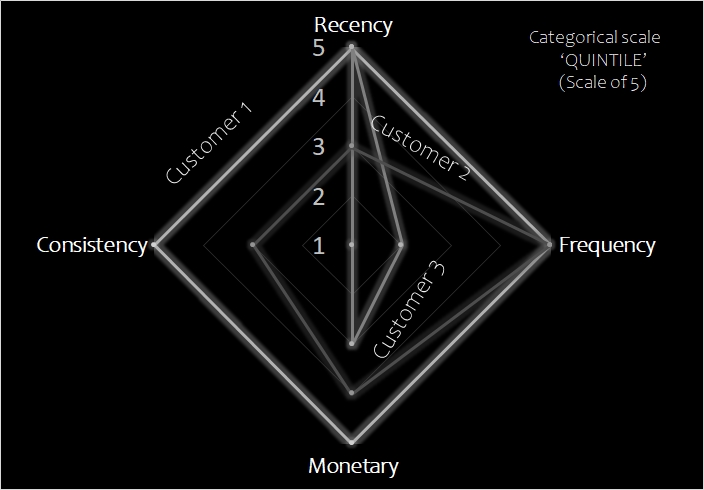
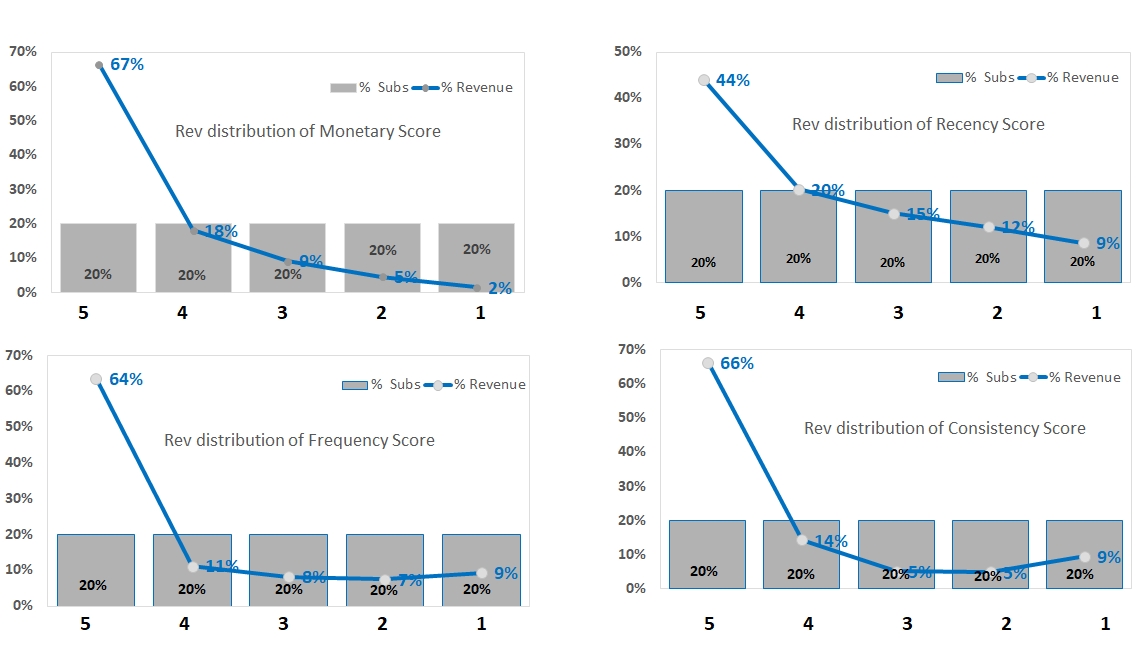
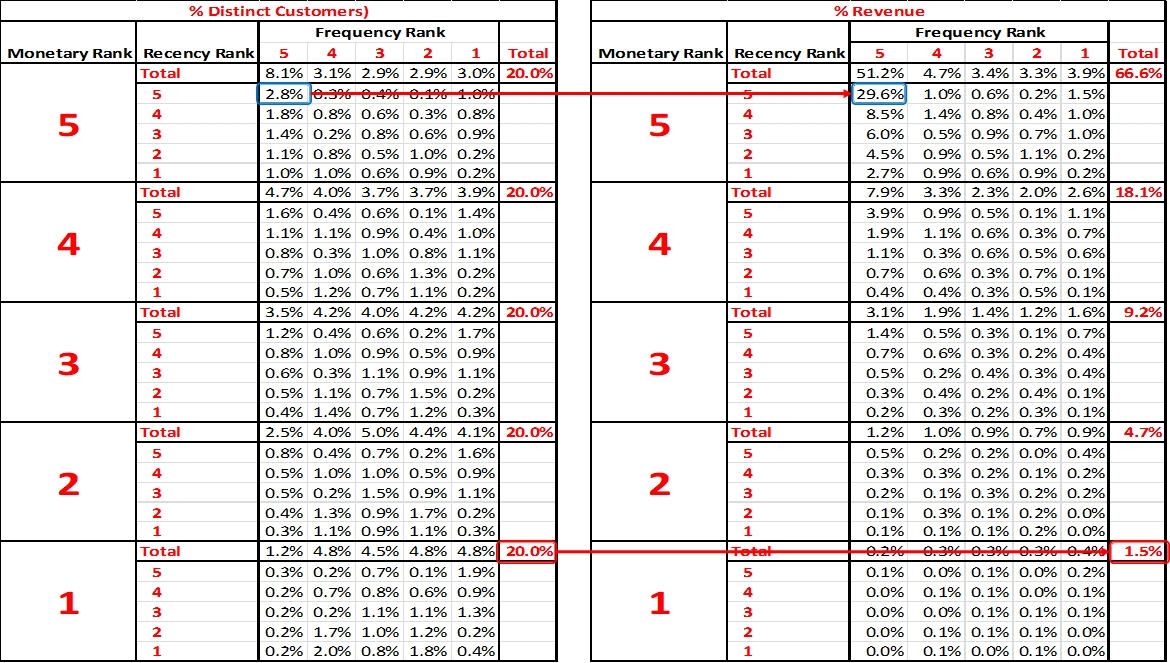
RFM Summary (Indicative Pattern)
20% of Customers contributing to 66.6% of revenue in top and only 1.5% of revenue in the bottom. Clearly not all customers can be treated the same way.
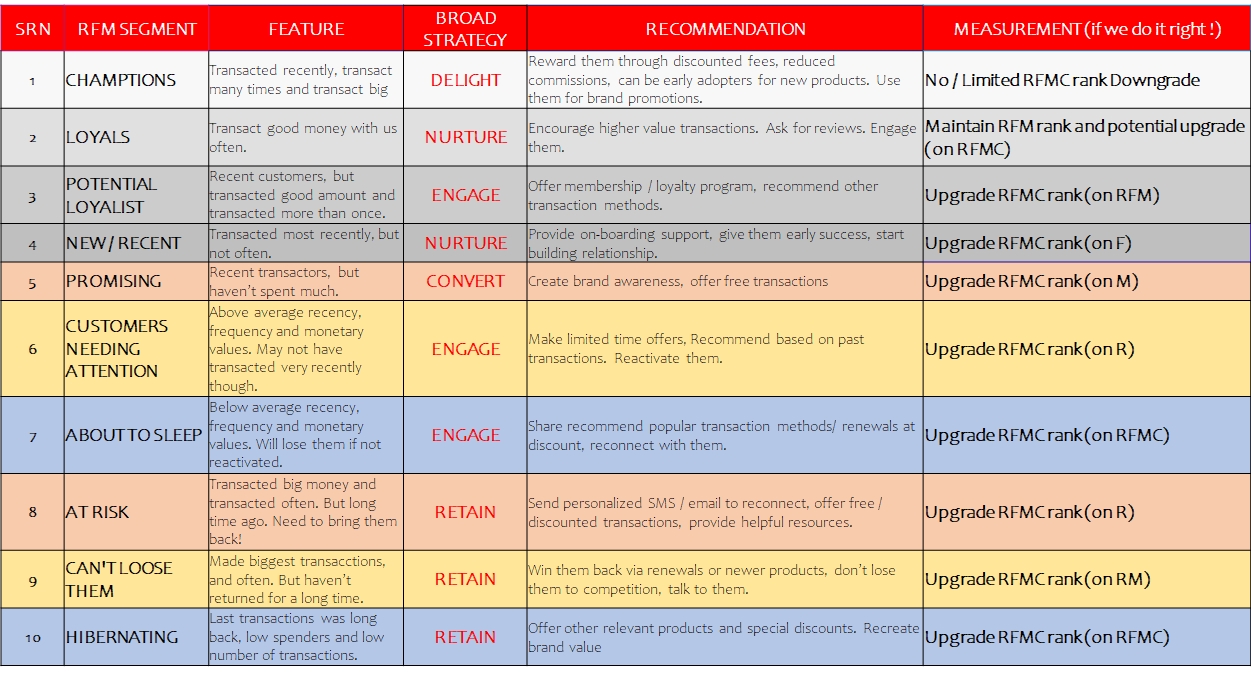
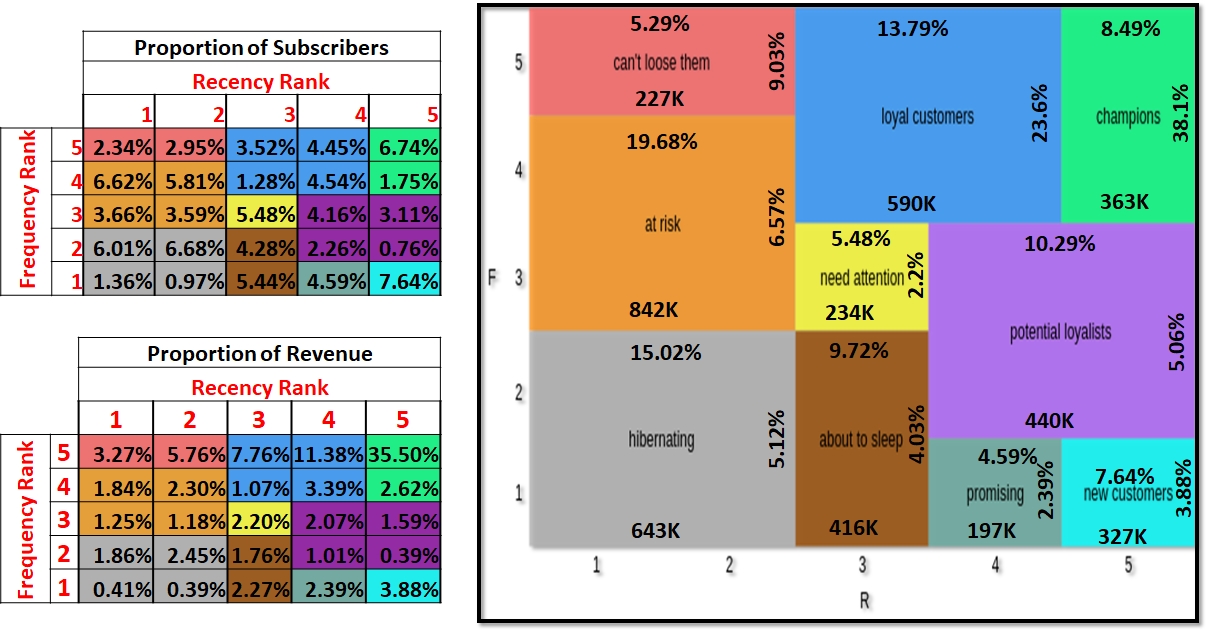
Commercial indicators from RFMC model (2 Dimensional)
10 Clear segments of Customer behavior just on 2 dimensions (Frequency and Recency). Using all 4 dimensions results in many micro-segments.
Recommended Actions - RFMC